
R语言基础笔记
1 | knitr::opts_chunk$set(echo = TRUE) |
本文参考李东风老师的R语言教程,并以Rmarkdown的格式写,使用的R版本是
4.2.3
楔子
今天又又又一次开始学习R语言了,之前在学概率论时候学过一次、上C语言时候又试过一次,但最后总是烂尾。其实这归根到底还是没有使用好这技能,生物学上,关于进化论有一句经典的概括—用进废退,越用越进化,不用就退化,你看看长颈鹿🦒的长脖子,鼹鼠的瞎眼,便是极为明显的例子。对于人类来讲,技能的习得也是一样的道理,使用地少而不遗忘几乎是不可能的事。谁知道我心里这把无名的热情过去后,还会存留什么呢?(很可能就是这几篇文章而已)
这回重新学习,直接原因是为了画好毕业论文中的图表。
其实中午干饭时候,在掌阅里搜了本Origin2022的教程,看了下,觉着也不太复杂,下午就试着用origin(破解版)画了个三维图。因为软件里有大量现成的例子,绘图的确是挺简单的,但是若想画出来一个理想的图,就不得不需要调节大量的细节了,点来点去,极为繁琐。
克劳斯·O.威尔克在《数据可视化基础》一书中提到:数据可视化要把自动化作为朋友,形成一个线性的工作流。图表应当做为流的一部分自动生成,而且要尽量避免后期的再处理(比如用R画了个图,又导到AI里美化等等)。他强调:一旦在后期对图表进行了手动编辑,图片就不再可能再现,返工也极为麻烦,分叉的流不是个完美的工作流!
不巧的是,上面克佬所说的这些痛点在origin中比比皆是:手动导入数据,手动编辑各个部分细节,手动导出,手动…这个流简直跟亚马逊河的支流一般了。虽然此软件也图表模板的功能作为补充,但是自动化程度还是太低,一点也不优雅。另外吐槽一句:origin2022最新版的界面在2023年着实吓到我了,简直梦回win7,公司里的设计师都被裁员了吗?真是令人哭笑不得。
但再理性地想想,工具本身并不会控制人,人才是工具的主宰,本着技多不压身的终身学习者人生信条,这origin还是要掌握的。毕竟这种所见即所得的软件入门极快,再稍稍掌握些技巧就可以得心应手了。
另一类绘图工具,如R语言、Python,或者莫若说一些数据可视化的宏包如ggplot等,则是这阶段主要去学习掌握的内容。这类工具虽然入门麻烦点,但是一旦可以熟练掌握,一通百通,后益无穷啊!
掌握数据可视化的共性才是最终目的。还是克佬说得好,数据可视化是科学性与艺术性的组合。不仅需要掌握各种绘图的技巧,更是要培养美学鉴赏力,这样才能绘制出来美观的图表。其实从某些方面讲,数据可视化跟摄影后期处理很是相似,即能力的提升与鉴赏力的提高是并行的。
先亮下这两天学习的成果
R语言基本要点
这部分内容是学习过程中,我认为有用的,值得去掌握的东西。不求全,只求精要而已。
数据结构
R语言数据结构包括向量,矩阵和数据框,多维数组, 列表,对象等。还可以用名字来直接访问数据中(csv表格)的元素、行、列。
使用 typeof()函数来查看变量的类型。
向量
向量在数据可视化中很常用,坐标轴的刻度往往就需要一个合适的向量来控制。
使用c()来可以生成一个简单的向量,比如21 22 23 1 5 9 7可以这样生成 > 同C语言等高级编程语言一样,R的变量名也有要求:变量需要由字母、数字、下划线、小数点组成, 开头不能是数字、下划线、小数点,中间不能使用空格、减号、井号等特殊符号, 变量名不能与if、NA等保留字相同。
1 | rabbit1 <- c(21:23,1,5,9,7) |
1 | rabbit1: 21 22 23 1 5 9 7 |
使用seq()函数,可以来生成指定增量的向量。比如从400开始,每50个数取一个值,直到1200的向量rabbit2。也可以生成指定间隔的向量,比如从400到1200之间分成13份的向量rabbit3
1 | rabbit2=seq(400,1200, by=50) |
1 | rabbit2: 400 450 500 550 600 650 700 750 800 850 900 950 1000 1050 1100 1150 1200 |
使用rep()函数,生成重复向量。比如一个长度为10的值全为6的变量rabbit6
1 | rabbit6 = rep(6,10) |
1 | rabbit6: 6 6 6 6 6 6 6 6 6 6 |
向量子集的选择
对向量x, 在后面加方括号和下标可以访问向量的元素和子集。
设x <- c(1, 4, 6.25)。 x[2]取出第二个元素; x[2] <- 99修改第二个元素。 x[c(1,3)]取出第1、3号元素; x[c(1,3)] <- c(11, 13)修改第1、3号元素。
x[-2]表示选择倒数第二个元素;
x[]表示选择x的所有元素;
x[x<6]表示选择所有小于6的元素。
1 | x <- seq(10,20) |
1 | [1] 10 11 12 13 666 15 16 17 18 19 20 |
还可以通过函数来进行选择,比如使用which函数来求出满足指定要求元素的下标。
1 | x <- seq(12,58,by=4) |
列表
R中列表(list)类型来保存不同类型的数据。列表可以有多个元素,但是与向量不同的是,列表的不同元素的类型可以不同, 比如, 一个元素是数值型向量, 一个元素是字符串, 一个元素是标量, 一个元素是另一个列表。 比如:list(name="路人甲", age=20,scores=c(85, 76, 90)) 列表元素访问使用[[ ]]
矩阵
矩阵用matrix()函数定义,实际存储成一个向量,根据保存的行数和列数对应到矩阵的元素, 存储次序为按列存储(从上到下,从左至右)。可以用colnames()、rownames()函数可以给矩阵每列、行命名。比如:
1 | rabbit7 <- matrix(1:10, nrow=5, ncol=2); |
1 | 天 地 |
数据框
数据框是R中一个非常重要的数据类型,类似于csv文件,在R中称作data.frame,数据可以手动输入或者自动抓取,在此以本站的十一个分类为例,着重介绍下如何进行数据的选择。
1 | zixu <- data.frame( |
当要选取第二列文章数量时,使用zixu[, 2],这跟matlab对矩阵选择的命令是一致的,也可以用名字直接选:zixu$文章数量
数据框不能作为矩阵参加矩阵运算。需要时,可以用as.matrix()函数转换数据框或数据框的子集为矩阵。
R中还有更高级的数据框tibble,可以将CSV文件读入为tibble类型,很是实用。
其他数据结构
这里先列些暂时用不上的数据类型,等到以后需要用了再详细补充。
逻辑型数据是R中的基本数据类型,只包含三个值:TRUE、FALSE与NA。比如快速求出大于某个值的数,就可以简单地这样写:
1 | seq(2000,2023) >= 2012 |
1 | [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE |
时间型数据:用library(lubridate)宏包来调用。
运算与函数
就平时用到的计算而言,就加减乘除、幂对三角函数而已:
1 | s1 = (2023+4+24-9)*36/51 |
1 | s1= 1441.412 ‖ s2= 2.004321 ‖ s3= 0.5 ‖ s4= 4092529 ‖ s44= 2023 |
一门语言最基本的就是函数了,R语言内置了许多数学函数,可以很方便的进行调用运算,比如标准正态分布的概率密度函数------dnorm。
考研复习的是数二,概率论已经忘干净了,这个函数大概是表示在平均值为0,标准差为1的正态分布下,一个给定值在这个分布函数内有多大概率出现,比如绝对值小于1.98的数在这个分布内有0.9438169的概率出现。
1 | 1-dnorm(1.98) |
1 | [1] 0.9438169 |
复合函数的调用还在用吗?已经OUT了,用管道运算符,可以更清晰的表现函数的流动,可以类比成复合函数求导中链式法则的一条链,上式的四条链可以写成:
x |> u() |> F()x |> v() |> F()y |> u() |> F()y |> v() |> F()
这里就以2023年考研数二第十八题的符合函数做个示范
R语言自定义函数也非常简单,用f <- \(x1,x2,x3x...)来定义,那么上式可以这样定义,再顺手定义一个展示函数show()
1 | f <- \(x,y) x*(exp(1))^{cos(y)}+(x^2)/2 |
1 | f( 2 , 1.570796 )= 4 |
🎵 谷雨微冷的晚上,图书馆里,边听jazz,边码字学习,真是太惬意了。😊
程序控制结构
就函数而言,无非是分支、循环结构。这里以最新一期《科学大观园·第664期》中《睡眠的低谷》一文中对于睡眠时间于认知能力的关系,使用选择分支`if-else`函数,写一个睡眠时间评估小函数:
1 | sleeptime <- \(x) |
循环结构可以使用for() while() repeat() 函数。
R语言基本绘图
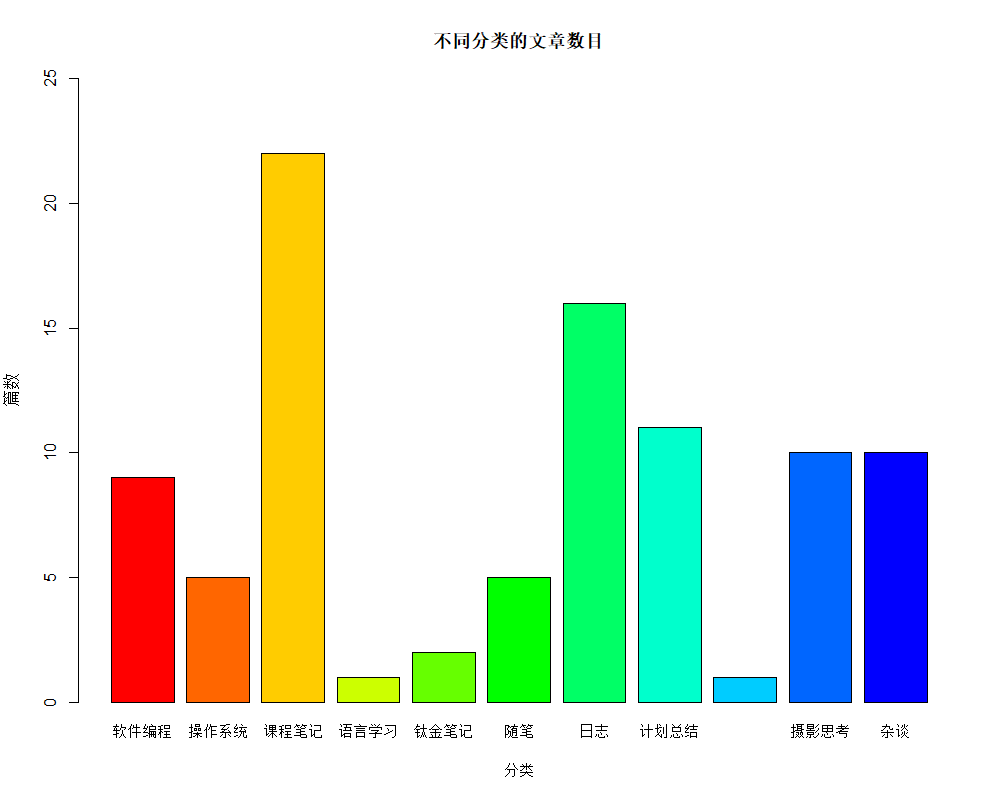
这里以上面博客分类文章的数据来绘制图形
条形图
1 | zixu <- data.frame( |
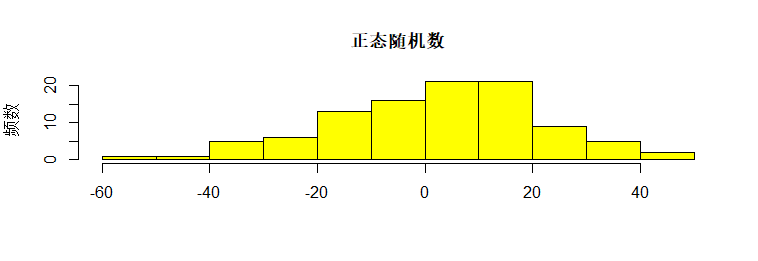
概率密度图
1 | x <- rnorm(30, mean=0, sd=20) |
rmarkdown简介及其与Hexo的联动
rmarkdown是一个与md文件语法一致。rmd也支持YAML front matter,而且除了date有冲突外,其他的配置都不冲突,可以很完美的兼容hexo各种插件的配置。具体的配置文件在这里 ### rmarkdown简单配置 rmd内置了目录与类似选项卡的插件: #### 目录
1 | output: |
选项卡式部分
使用
{.tabset .tabset-fade .tabset-pills}来生成药丸风格的样式
1 | ## Quarterly Results {.tabset} |
主题
默认主题有许多,但是比较呆板,可以安装几个附加的 R 包来实现更多的 R Markdown HTML 主题。例如 prettydoc、rmdformat、hrbrthemes、tufte 和 tint。
与本站风格比较匹配的是这个给名为cayman的主题(依赖prettydoc宏包),在front matter中修改下配置就好了(会失去对选项卡功能的支持)
1 | output: |
hexo联动
其实一开始我是准备用yihui大佬的blogdown新建一个支持rmd的hugo站点来着,但是很浪费时间。又看到rmd生成的仅仅是一个html文件[1],没有外部依赖,便想到利用<iframe>标签嵌入到文章。
试验了一下,果然非常优雅,而且还很好的支持了echars4r的交互式绘图,棒棒哒!
1 | <iframe style="border-radius:12px" src="/pdf/R/learn-echars4r.html" width="100%" height="719.8" frameBorder="0" allowfullscreen="" allow="autoplay; clipboard-write; encrypted-media; fullscreen; picture-in-picture" loading="lazy"></iframe> |
R Markdown 生成没有外部依赖项的独立 HTML 文件,使用 URI 合并链接脚本、样式表、图像和视频的内容。 ↩︎

