CREATE FUNCTION `mes_prod`.`parent_chain`(so_present VARCHAR(50)) RETURNS varchar(50) CHARSET utf8mb4 COLLATE utf8mb4_bin READS SQL DATA BEGIN DECLARE so_parent VARCHAR(50); SELECT so.parent_shop_order INTO so_parent FROM so WHERE so.shop_order = so_present AND so.parent_shop_order != so_present LIMIT 1; RETURN so_parent; END
SELECT srso.sfc 钢卷号, srso.batch 批次号, srso.end_date_time_lt 生产结束时间, srso.inspect_order 入库检验批号, so.shop_order 终结工单, -- srs.operation_desc 末工序, -- srs.plan_next_station 流向, srso.next_storage_location_desc 实际流向, parent_chain(so.shop_order) 父工单, parent_chain(parent_chain(so.shop_order)) 父父工单, parent_chain(parent_chain(parent_chain(so.shop_order))) 父父父工单, parent_chain(parent_chain(parent_chain(parent_chain(so.shop_order)))) 父父父父工单, parent_chain(parent_chain(parent_chain(parent_chain(parent_chain(so.shop_order))))) 父父父父父工单, parent_chain(parent_chain(parent_chain(parent_chain(parent_chain(parent_chain(so.shop_order)))))) 父父父父父父工单 FROM so LEFT JOIN so_status_view ssv ON so.id = ssv.main_table_id LEFT JOIN so_router_step srs ON srs.main_table_id = so.id AND srs.is_last_operation = '1' AND srs.is_last_operation IS NOT NULL LEFT JOIN so_router_step_out srso ON srso.detail_table_id = srs.id WHERE ssv.so_status != '在制工单' AND (srso.next_storage_location_desc != '余材仓' AND srso.next_storage_location_desc != '半成品仓') AND srso.end_date_time_lt >= TIMESTAMP(DATE_FORMAT(CURDATE(), '%Y-%m-01'), '00:00:00') -- AND srso.batch = '2601160012' -- 批次筛选 -- AND srso.sfc ='Y30125122302AE0102' -- 钢卷号筛选 AND parent_chain(so.shop_order) IS NULL -- 单工单筛选 ORDER BY srso.end_date_time_lt -- 按时间正序
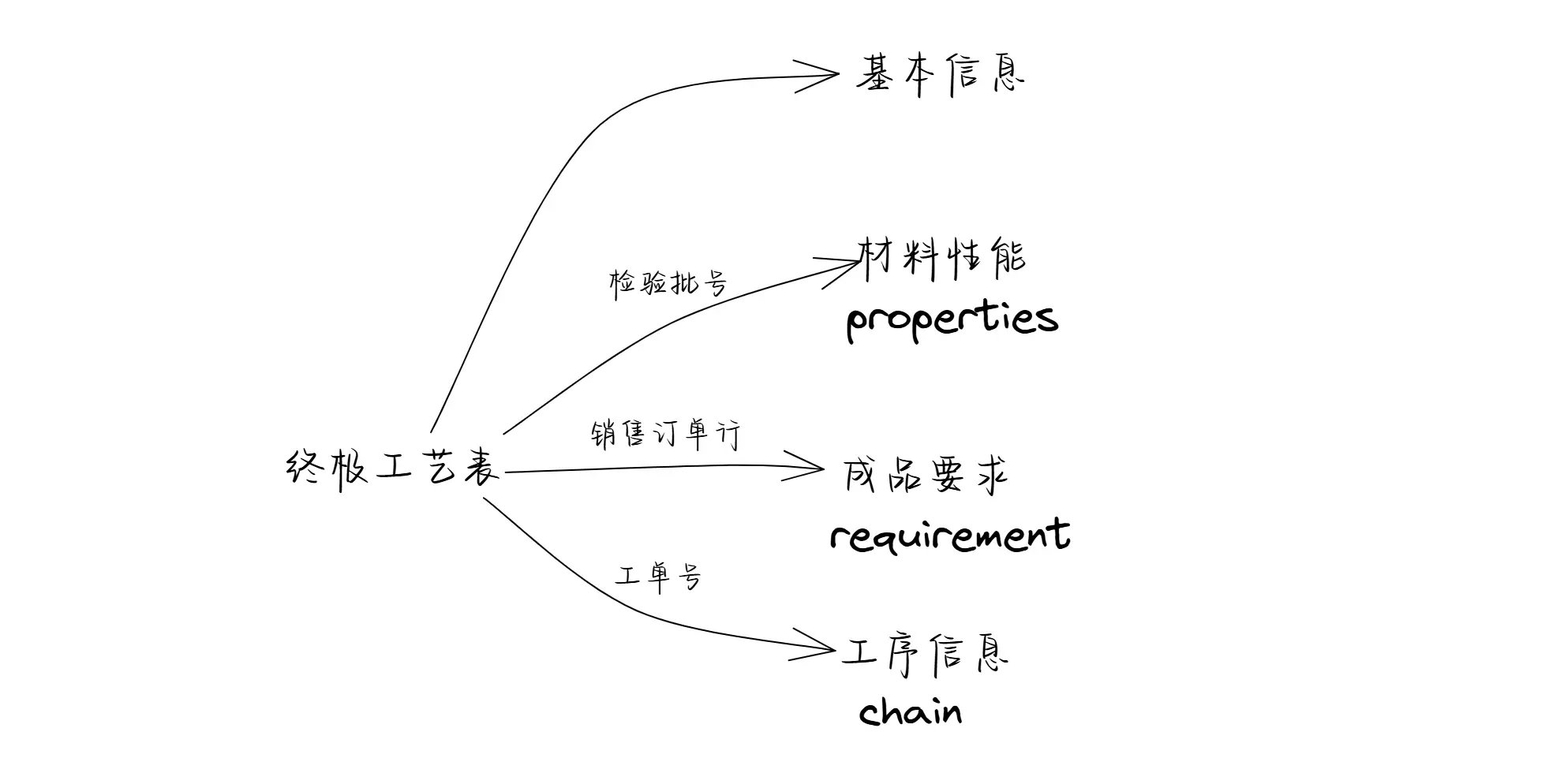
SELECT o.zt210 钢卷号, -- 宽度、厚度、重量、钢种等基本信息 qil.inspect_lot 检验批号, -- 连接材料性能视图properties,桥接字段为`检验批号` o.zt180 销售订单行, -- 连接成品要求视图requirement,桥接字段为`销售订单行` LEFT(p.zmesgd, 12) 工单号, -- 连接工序信息,桥接字段为末工单号 FROM mes_prod.material_out_data o LEFT JOIN mes_prod.post p ON p.id = o.main_table_id LEFT JOIN mes_prod.sl ON sl.storage_location = o.lgort LEFT JOIN wms_prod.inspect_lot_source ils ON ils.batch_number = o.batch LEFT JOIN wms_prod.qm_inspect_lot qil ON qil.id = ils.main_table_id WHERE LOCATE('213', o.matnr, 1) AND o.zt10 > DATE_SUB(CURDATE(), INTERVAL 2 DAY)
# 获取源工单(末工单) cursor.execute(""" SELECT LEFT(p.zmesgd, 12) as work_order FROM mes_prod.material_out_data o LEFT JOIN mes_prod.post p ON p.id = o.main_table_id WHERE LOCATE('213', o.matnr, 1) -- AND o.zt10 > DATE_SUB(CURDATE(), INTERVAL 2 DAY) GROUP BY work_order HAVING work_order = 'S20251113013' LIMIT 500 """)
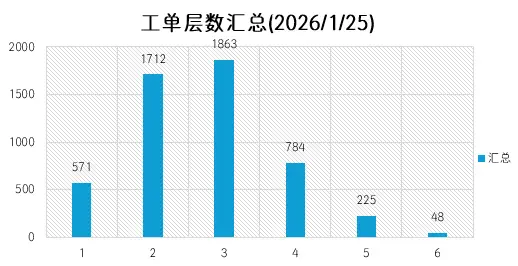
source_orders = [row['work_order'] for row in cursor.fetchall()] all_data = [] work_order_hierarchy = {}
# 处理每个源工单 for source_order in source_orders: # 构建工单层级链 chain = [source_order] current_order = source_order whileTrue: cursor.execute("SELECT parent_chain(shop_order) as parent FROM so WHERE shop_order = %s", (current_order,)) parent_result = cursor.fetchone() ifnot parent_result ornot parent_result['parent'] or parent_result['parent'] == 'NULL': break chain.append(parent_result['parent']) current_order = parent_result['parent'] iflen(chain) > 10: break # 分配层级(最顶层为1) for i, work_order inenumerate(reversed(chain)): level = i + 1 is_last_order = (work_order == source_order) # 查询工序 cursor.execute(""" SELECT step.sequence, step.operation_desc FROM so LEFT JOIN so_router_step step ON step.main_table_id = so.id WHERE so.shop_order = %s AND step.status!= 'NEW' AND step.status!='REL' ORDER BY step.sequence """, (work_order,)) processes = cursor.fetchall() for process in processes: converted_seq = f"{int(process['sequence']) // 10:02d}" hierarchy_code = f"{level}{converted_seq}" all_data.append({ '源工单': source_order, '当前工单': work_order, '层级': level, '是否末工单': '是'if is_last_order else'否', '工序描述': process['operation_desc'], '层级编码': hierarchy_code, '编码数值': int(hierarchy_code) }) # 存储层级信息 if source_order notin work_order_hierarchy: work_order_hierarchy[source_order] = [] work_order_hierarchy[source_order].append({ '工单号': work_order, '层级': level, '是否末工单': is_last_order })